- 您好!欢迎来到鲲鹏知舟
NÜWA:用于神经视觉世界创建的视觉合成预训练
本文提出了一个统一的多模态预训练模型,称为 NÜWA,可以为各种视觉合成任务生成新的或操纵现有的视觉数据(即图像和视频)。针对不同场景同时覆盖语言、图像和视频,设计了3D Transformer编码器-解码器框架,不仅可以将视频作为3D数据处理,还可以分别将文本和图像作为1D和2D数据进行适配. 还提出了 3D Nearby Attention (3DNA) 机制来考虑视觉数据的性质并降低计算复杂度。我们在 8 个下游任务上评估 NÜWA。与几个强大的基线相比,NÜWA 在文本到图像生成、文本到视频生成、视频预测等方面取得了最先进的结果。此外,它还在文本引导的图像和视频操作任务中显示出令人惊讶的出色零镜头能力。项目回购是 这个 https 网址。
更详细附件:![]() 下载
下载
概述
这是论文的官方存储库:NÜWA: Visual Synthesis Pre-training for Neural visUal World CreAation。
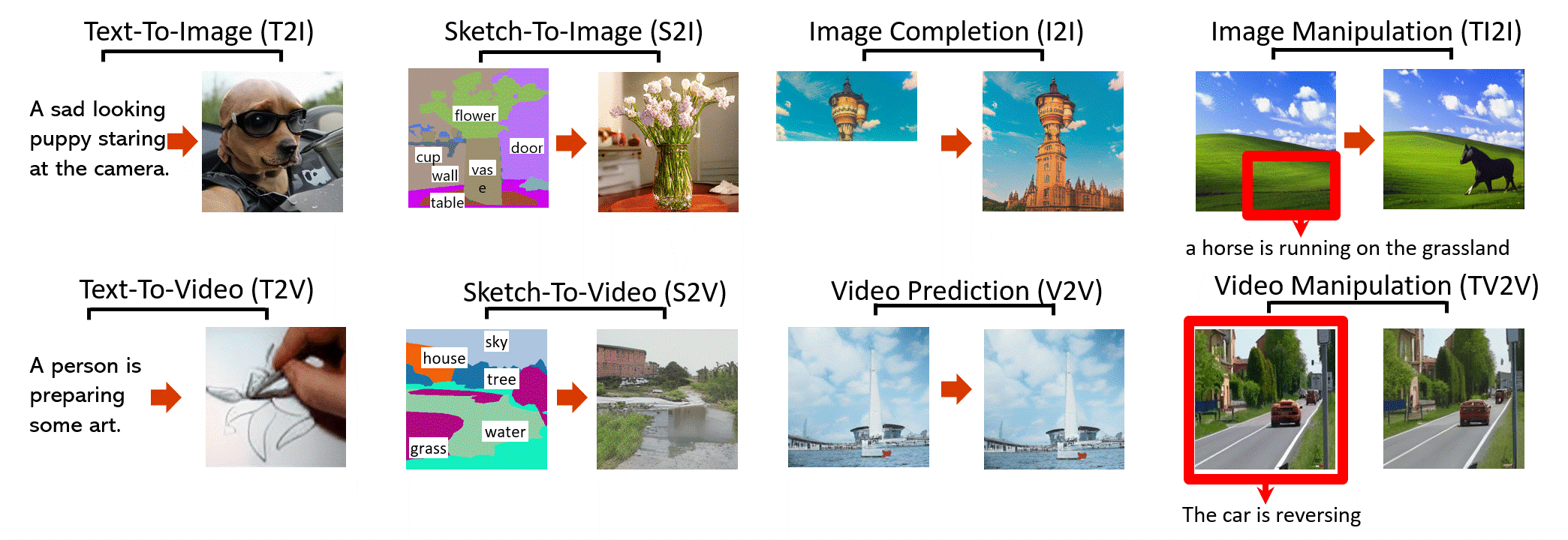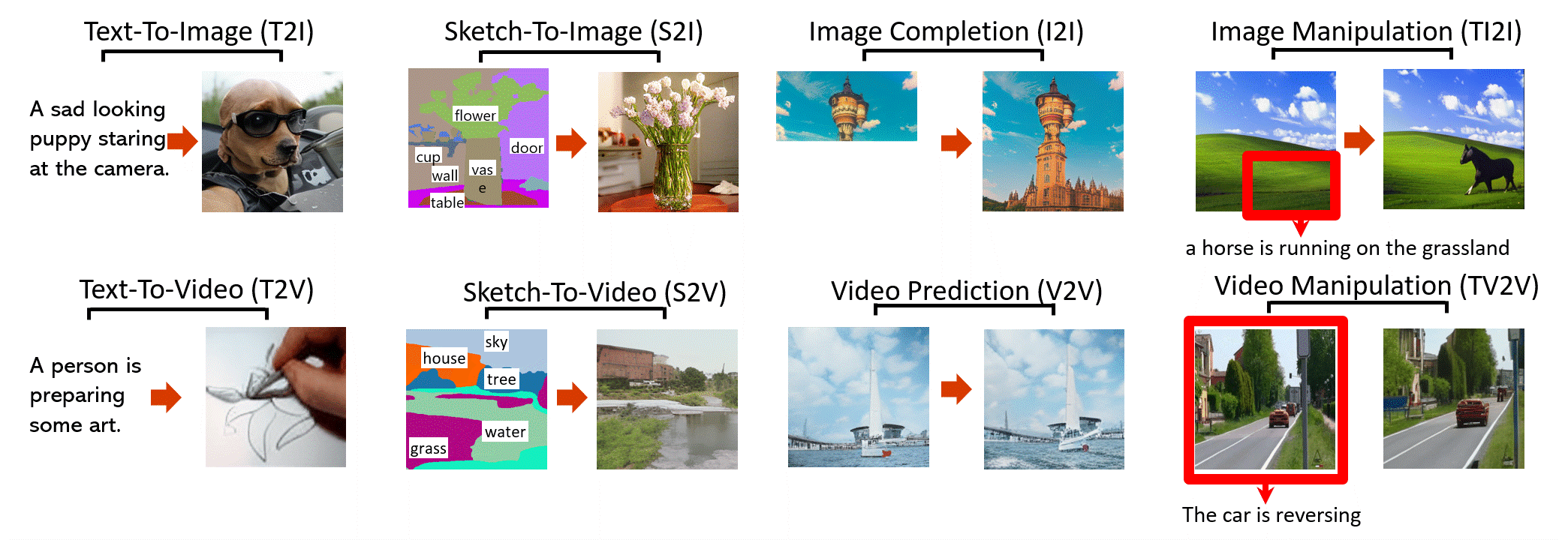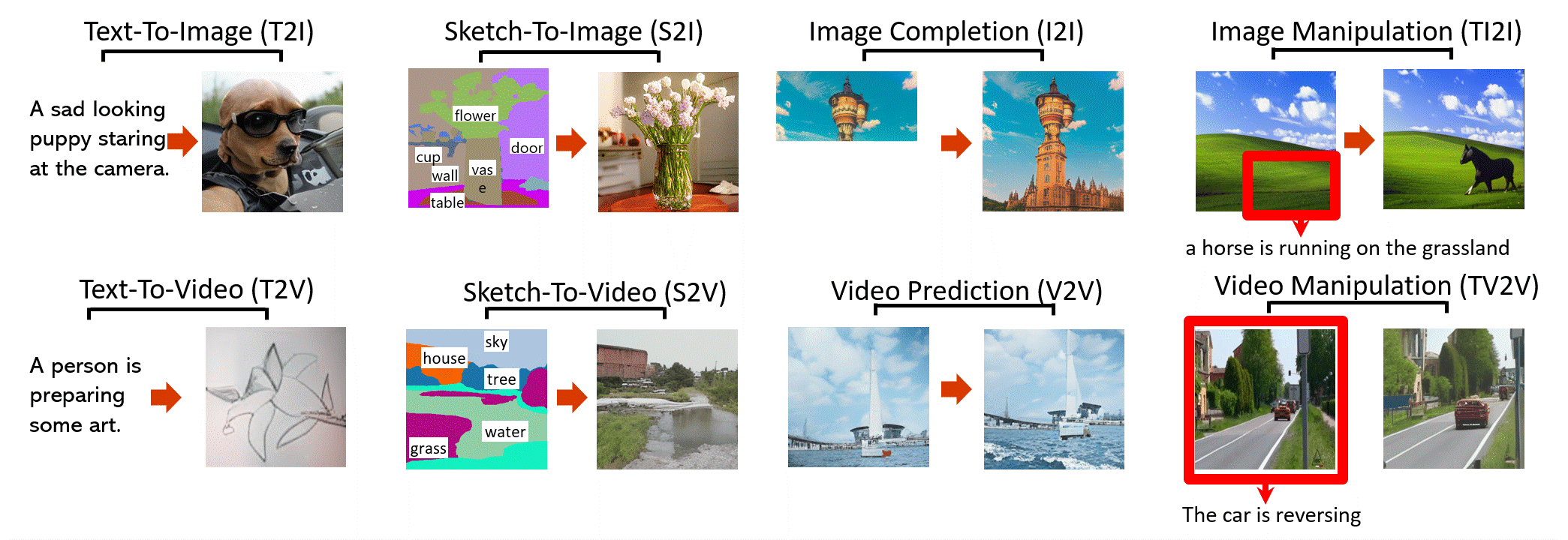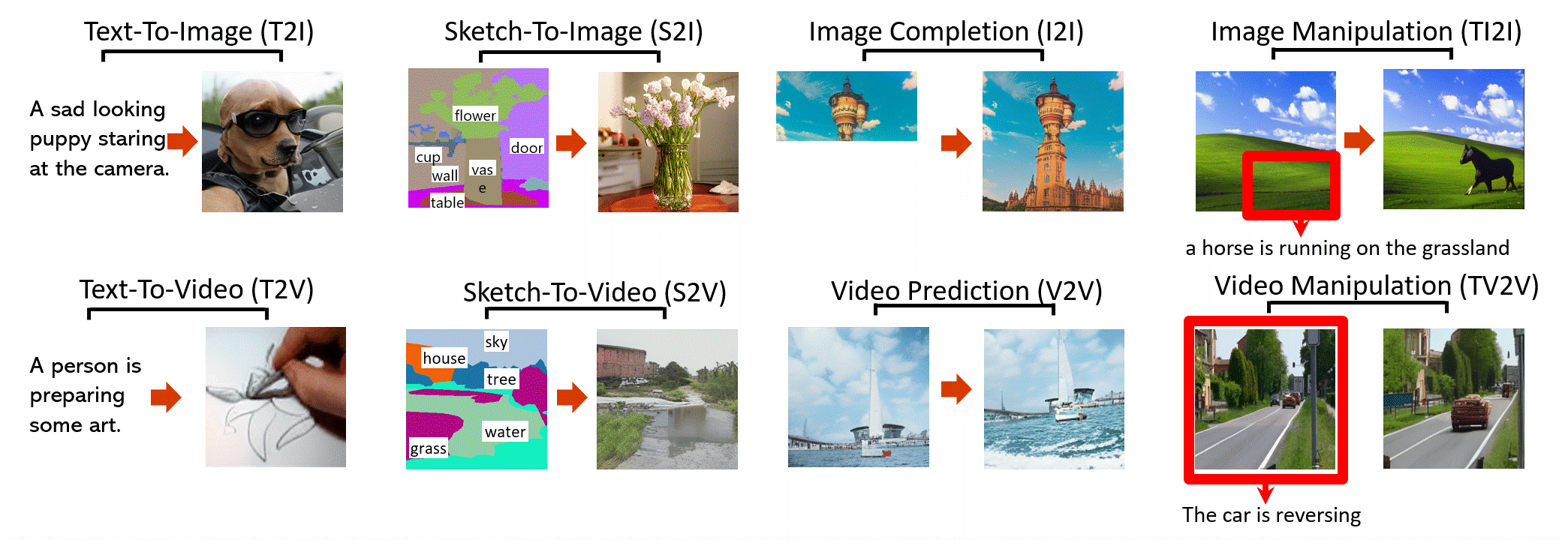
NÜWA 是一个统一的多模态预训练模型,可以为8 个视觉合成任务(如上图)生成新的或操纵现有的视觉数据(即图像和视频)。
样品
文本到图像 (T2I)

草图到图像 (S2I)

图像补全 (I2I)

文本引导图像处理 (TI2I)
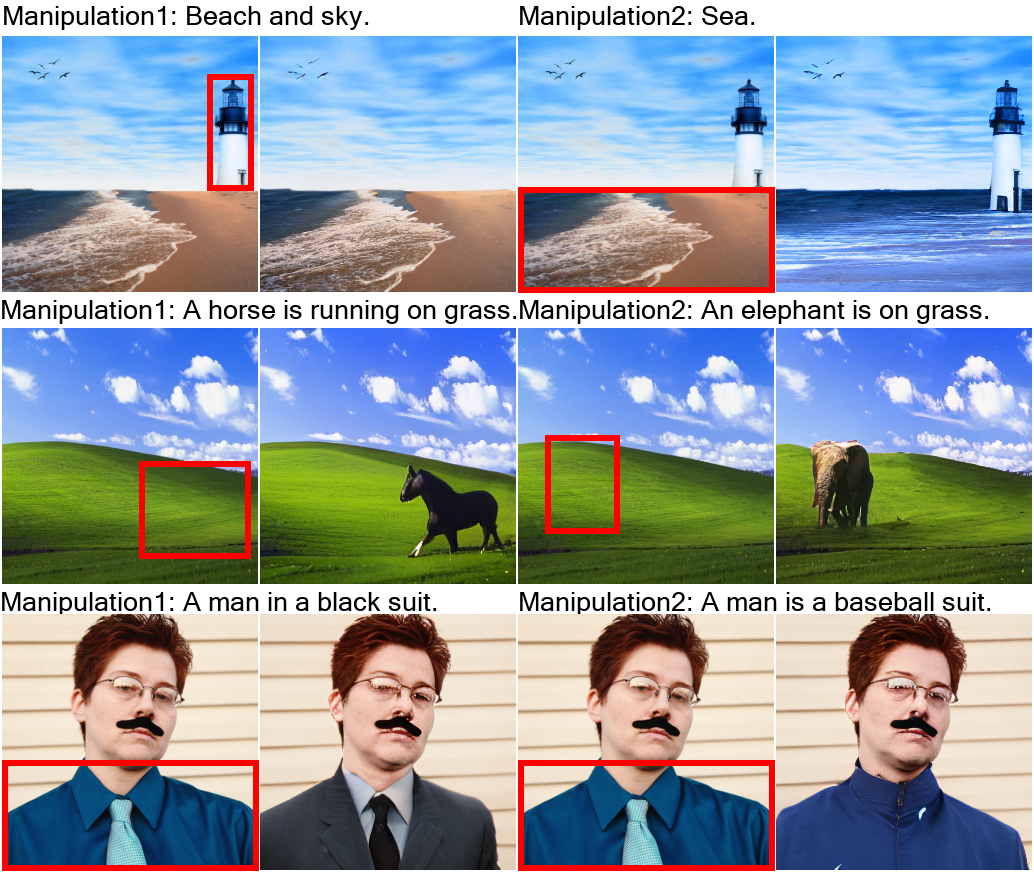
文字转视频(T2V)

视频预测 (V2V)

草图到视频 (S2V)

文本引导的视频操作 (TV2V)

-
使用社交账号登录,本站支持
全部评论(0)