在机器学习领域取得成功或成为一名伟大的数据科学家的关键是练习不同类型的数据集。但是为每种机器学习项目找到合适的数据集是一项艰巨的任务。因此,在本主题中,我们将提供来源的详细信息,您可以根据自己的项目轻松获取数据集。
在了解机器学习数据集的来源之前,让我们先讨论一下数据集。
数据集是数据按某种顺序排列的数据集合。数据集可以包含从一系列数组到数据库表的任何数据。下表显示了数据集的示例:
| 国家 | 年龄 | 薪水 | 已购买 |
|---|---|---|---|
| 印度 | 38 | 48000 | 不 |
| 法国 | 43 | 45000 | 是的 |
| 德国 | 30 | 54000 | 不 |
| 法国 | 48 | 65000 | 不 |
| 德国 | 40 | 是的 | |
| 印度 | 35 | 58000 | 是的 |
表格数据集可以理解为数据库表或矩阵,其中每一列对应一个特定的变量,每一行对应数据集的字段。表格数据集最受支持的文件类型是“逗号分隔文件”或CSV。但是为了存储“树状数据”,我们可以更有效地使用 JSON 文件。
数值数据:如房价、温度等。
分类数据:如是/否、真/假、蓝/绿等。
序数数据:这些数据类似于分类数据,但可以在比较的基础上进行测量。
要处理机器学习项目,我们需要大量数据,因为没有数据,就无法训练 ML/AI 模型。在创建 ML/AI 项目时,收集和准备数据集是最关键的部分之一。
如果数据集没有做好充分的准备和预处理,任何 ML 项目背后应用的技术都无法正常工作。
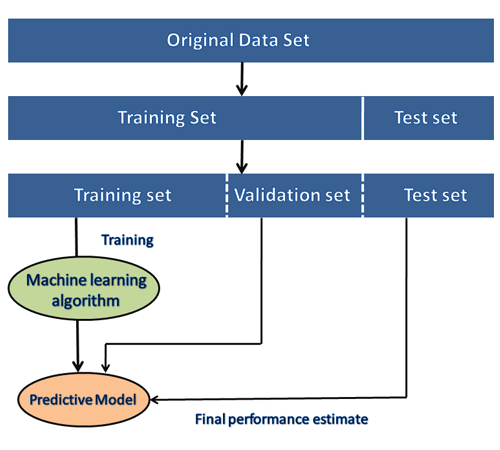
在 ML 项目的开发过程中,开发人员完全依赖于数据集。在构建 ML 应用程序时,数据集分为两部分:
训练数据集:
测试数据集
以下是可供公众免费使用的数据集列表:
Kaggle 是为数据科学家和机器学习者提供数据集的最佳来源之一。它允许用户以简单的方式查找、下载和发布数据集。它还提供了与其他机器学习工程师合作并解决与数据科学相关的困难任务的机会。
Kaggle 提供了不同格式的高质量数据集,我们可以轻松找到和下载。
Kaggle 数据集的链接是https://www.kaggle.com/datasets。
UCI 机器学习存储库是机器学习数据集的重要来源之一。该存储库包含机器学习社区广泛用于分析 ML 算法的数据库、领域理论和数据生成器。
自 1987 年以来,它已被学生、教授、研究人员广泛用作机器学习数据集的主要来源。
它根据机器学习的问题和任务对数据集进行分类,例如回归、分类、聚类等。它还包含一些流行的数据集,例如Iris 数据集、Car Evaluation 数据集、Poker Hand 数据集等。
UCI 机器学习存储库的链接是https://archive.ics.uci.edu/ml/index.php。
我们可以搜索、下载、访问和共享通过 AWS 资源公开可用的数据集。这些数据集可以通过 AWS 资源访问,但由不同的政府组织、研究机构、企业或个人提供和维护。
任何人都可以通过 AWS 资源使用共享数据分析和构建各种服务。云端共享数据集帮助用户将更多时间花在数据分析上,而不是数据的获取上。
此来源提供了各种类型的数据集以及使用数据集的示例和方法。它还提供了搜索框,我们可以使用它来搜索所需的数据集。任何人都可以将任何数据集或示例添加到AWS 上的开放数据注册表。
该资源的链接是https://registry.opendata.aws/。
谷歌数据集搜索引擎是谷歌于2018年9 月 5 日推出的搜索引擎。该源帮助研究人员获取可免费使用的在线数据集。
Google 数据集搜索引擎的链接是https://toolbox.google.com/datasetsearch。
微软推出了“微软研究开放数据”存储库,其中收集了自然语言处理、计算机视觉和特定领域科学等各个领域的免费数据集。
使用这个资源,我们可以下载数据集在当前设备上使用,也可以直接在云基础设施上使用。
从该资源下载或使用数据集的链接是https://msropendata.com/。

Awesome public dataset collection 提供了高质量的数据集,这些数据集根据农业、生物学、气候、复杂网络等主题在列表中以组织良好的方式排列。大多数数据集是免费提供的,但有些可能不是,所以最好在下载数据集之前检查许可证。
从 Awesome 公共数据集集合下载数据集的链接是https://github.com/awesomedata/awesome-public-datasets。
有不同的来源可以获取与政府相关的数据。各国公布政府数据供公众使用,由他们从不同部门收集。
提供这些数据集的目的是提高政府工作的透明度,并以创新的方式使用数据。以下是政府数据集的一些链接:
视觉数据提供了多个特定于计算机视觉的优秀数据集,例如图像分类、视频分类、图像分割等。 因此,如果您想建立一个深度学习或图像处理项目,那么您可以参考这个来源。
从此来源下载数据集的链接是https://www.visualdata.io/。
Scikit-learn 是机器学习爱好者的重要资源。该来源提供了玩具和现实世界的数据集。这些数据集可以从 sklearn.datasets 包和使用通用数据集 API 获得。
scikit-learn 上可用的玩具数据集可以使用一些预定义的函数加载,例如load_boston([return_X_y])、load_iris([return_X_y])等,而不是从外部源导入任何文件。但是这些数据集并不适合现实世界的项目。
从此源下载数据集的链接是https://scikit-learn.org/stable/datasets/index.html。